partition

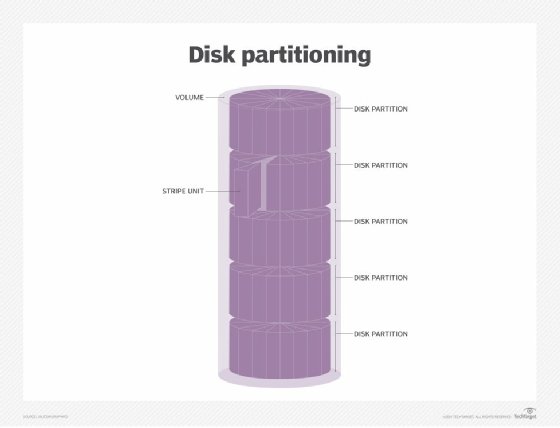
A partition is a logical division of a hard disk that is treated as a separate unit by operating systems (OSes) and file systems. The OSes and file systems can manage information on each partition as if it were a distinct hard drive. This allows the drive to operate as several smaller sections to improve efficiency, although it reduces usable space on the hard disk because of additional overhead from multiple OSes.
A disk partition manager allows system administrators to create, resize, delete and manipulate partitions, while a partition table logs the location and size of the partition. Each partition appears to the OS as a distinct logical disk, and the OS reads the partition table before any other part of the disk.
Once a partition is created, it is formatted with a file system such as:
- NTFS on Windows drives;
- FAT32 and exFAT for removable drives;
- HFS Plus (HFS+) on Mac computers; or
- Ext4 on Linux.
Data and files are then written to the file system on the partition. When users boot the OS in a computer, a critical part of the process is to give control to the first sector on the hard disk. This includes the partition table that defines how many partitions will be formatted on the hard disk, the size of each partition and the address where each disk partition begins. The sector also contains a program that reads the boot sector for the OS and gives it control so that the rest of the OS can be loaded into random access memory.
A key aspect of partitioning is the active or bootable partition, which is the designated partition on the hard drive that contains the OS. Only the partition on each drive that contains the boot loader for the OS can be designated as the active partition.
The active partition also holds the boot sector and must be marked as active. A recovery partition restores the computer to its original shipping condition.
In enterprise storage, partitioning helps enable short stroking, a practice of formatting a hard drive to speed performance through data placement.





